The deployment gap :
-> You finally finished your prototype, the team is relieved, test scores and lab benchmarks are strong, you are optimistic, time to test it in the real world.
the moment you slightly change the environment, things start to fall apart.
you see reduced confidence scores, errors out of the scope you thought possible, and you are forced to leave one of your engineers babysitting your creation around the clock.
nothing is below you, duct tape, silicon bevels, superglue, different manual bumpers, anything that can introduce some control and squeeze in some uptime.
you knew that the robot won't be as good in the wild, but you never imagined it will be this bad
this post will tell you the reality of deployed engineers ( and Im sure this is just a summary of the everyday suffering that they go through )
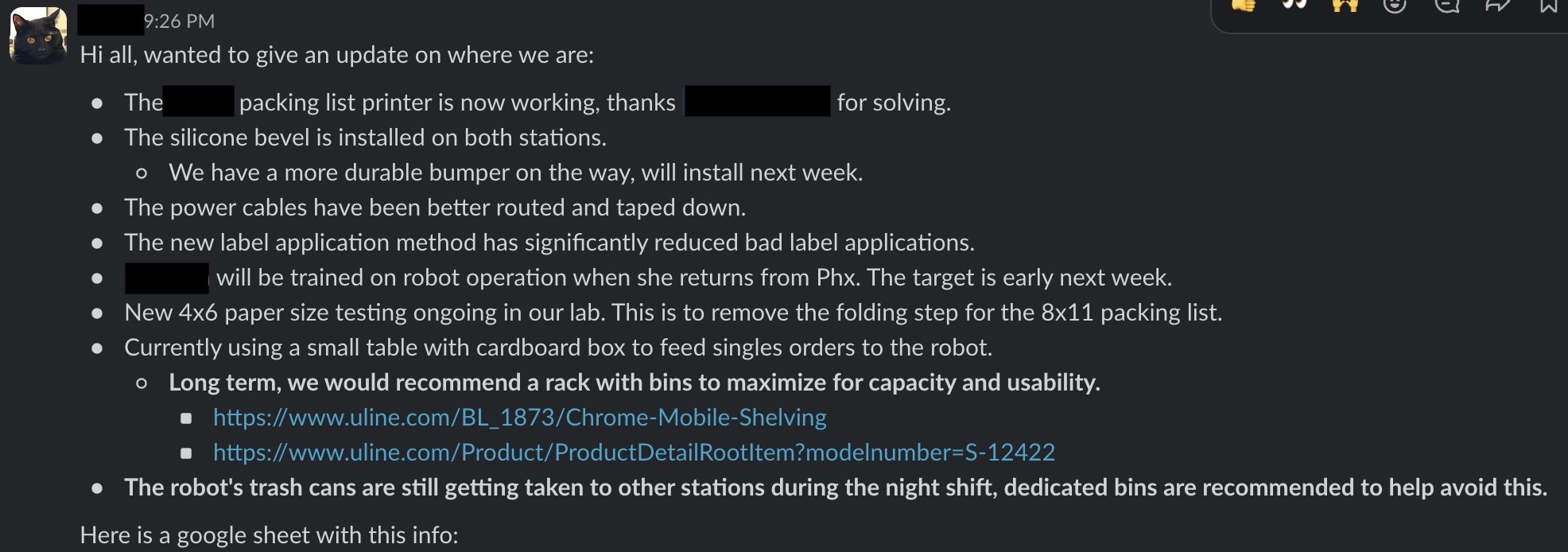
https://x.com/JonMSchwartz/status/2055101344395014480
the real work starts the moment a bunch of prototypes / MVPs are ready to deploy.
over the next upcoming months ( if not years ) you will be bombarded with performance issue reports, bugs, reliability shortcomings, and complaints about unexpected behaviors, and each one of these will probably require one if not many design and engineering changes across both your software and hardware stacks.
what do customers want to hear :
if you want to convince a customer to pay you a few thousand to tens of thousands of dollars per unit for a robot, you have to give them reliable uptime, maintenance costs, and what are the failure modes.
this is very tricky as these are learned policies on top of new robots, you cannot confidently provide a deterministic number for a stochastic system.
and here comes, in our opinion, one of the most important practices, what is called reliability engineering for learned systems.
why learned systems are different :
with traditional software, you can usually trace a bug to a deterministic condition, a state, or a line of code, but with learned systems the behavior is probabilistic, the model might work 96 times and then fail in the 97th run because the lighting, calibration, object pose, floor friction, or sensor noise shifted slightly.
deployment reliability :
Robot deployment reliability is the measured confidence that a robot behavior will keep succeeding under the real conditions it is expected to face.
for a deployment to be reliable, you need to have a combination of systems and guardrails, because honestly its near impossible to guarantee that a robot is going to work 100% of the time the way it should.
but introducing different mechanisms for better error handling, prediction of failure points, and alarming deployment teams when confidence is low goes a long way in making sure the next generation of robots is more prepared.
- graceful failure modes
- degradation aware systems : these systems report that they operate under unfamiliar settings and request operator assistance instead of just failing.
- robust tooling that can map tens of changes to concrete deployment outcomes ( whether good or bad ones ), where asking the question becomes : "what went wrong ?" to "this combination of changes (over few weeks or months ) degraded the perception accuracy"
- mixed systems, where a learned policy operates most of the time but when something goes wrong a predictable fallback takes control and doesn't cause more harm to the robot itself, people, or surroundings.
failure mode diagnostics :
usually this is done by a "triage" team, which when something goes wrong, you summon them to try to diagnose what happened and why it happened, and the more complex your robot is, the more people that have worked on it, the more time consuming and daunting of a role this becomes, as you have to coordinate with the integration team trying to understand what combination of recent changes caused this x behavior at this point in time.
how things are being done now :
a robot is a complex system, of various hardware and software components that need to work together to achieve a task or a goal, when you think about it from an engineering perspective each update will have many changes, both on the hardware and software levels.
any minor update or change will need a coordinated effort between different engineers if not different engineering teams.
let's think of a small scenario, a roomba robot, you know those robots that run around and clean your apartment, we finish the QA prototype and we send it for a few spins,
after those first few spins, we might come into some lackings or issues :
- corners are not well done
- carpet vacuuming is not as good
- it misses some zones especially if its under a table
now this report that will be done based on what the team inspects and what the logs show in these runs, would need to be inspected by the engineering team, and deciding what other attempts.
the hard part is not just deciding the next attempt, its knowing which change actually moved the behavior. did the new model improve carpet vacuuming but make corner handling worse? did a small calibration shift make the robot miss zones under tables? did a bumper change fix one surface and create a new failure mode somewhere else?
our approach trying to alleviate the deployment pain :
the goal is to give deployment teams a way to capture every run, track what changed across the robot stack, and map those changes to concrete outcomes.
not just "the robot got worse", but "this model version, with this calibration state, under these environment conditions, degraded this behavior compared to the previous baseline."
what needs to be tracked :
- model version
- model artifacts
- policy artifacts
- code
- hardware configs
- calibration state
- env conditions
- task definition
building a defensible reliability score :
- number of test runs
- success rate
- tested conditions
- untested conditions
- baseline comparison
- confidence level
- failure modes observed
- regressions introduced
- improvements introduced
- conditions where the robot should not be deployed yet
robot deployment reliability checklist :
this is the simple version of the checklist I would want before I trust a learned robot policy in a customer workflow, not because it guarantees anything, but because it stops everyone from arguing from memory.
every time the robot gets better or worse, you want to know what changed and what stayed the same :
- which model version is running ?
- which model artifacts and policy artifacts were deployed ?
- what code changed since the last working baseline ?
- what hardware changed, even if it feels too small to matter ?
- what calibration state was the robot in during the test ?
- what environment conditions were present during the run ?
- was the task definition exactly the same as the previous run ?
- how many runs were actually tested, not just watched once ?
- what failed, what almost failed, and what needed human help ?
- what conditions should block deployment until we test more ?
the point is not to make a perfect score, the point is to stop pretending that "it worked in the lab" means the robot is ready for a warehouse, a hospital, a farm, or someone's home.
what this changes :
instead of asking "why did the robot fail ?", the team can start asking "what changed before this failure started showing up ?"
and instead of giving customers vague reliability claims, deployment teams can show what was tested, what was not tested, where confidence is strong, and where the robot still needs more work.
the goal is not to pretend robots will work 100% of the time.
the goal is to know where they work, where they break, what changed, and how much confidence you actually have before sending them into the real world.
Join the pilot waitlist